

Jeśli to czytasz, zapewne słyszałeś już termin Kubernetes. Zapewne czytałeś już gdzieś, że jest to narzędzie do orkiestracji kontenerów, że ma jakieś powiązania z Dockerem, że używa się tego w chmurach, że ma super mechanizm automatycznego skalowania i że jest rozwiązaniem na wszelkie zło panujące przy ciągle rosnącym środowisku produkcyjnym.
Jednocześnie jednak masz świadomość, że nie jest to łatwa technologia, ponieważ prawie wszędzie czytasz, że próg wejścia w tę technologię jest wysoki, a gdy próbujesz ruszyć coś z dokumentacją Kubernetesa, ciężko Ci się zmierzyć z ogromem różnych nowych terminów.
Na dodatek gdy próbujesz uruchomić środowisko u siebie na komputerze, to ciągle coś nie działa, a oficjalna dokumentacja wydaje Ci się niejasna i zbyt ogólnikowa.
Zgadłem? Jeśli nie to bardzo przepraszam. Ale właściwie dlaczego zakładam, że jesteś taką osobą? Bo w rozmowach o Kubernetesie z innymi, właśnie z takimi osobami najczęściej się spotykałem. W tym artykule chcę udowodnić, że Kubernetes nie jest tak trudny jak się wydaje i można o nim opowiedzieć nieco... prościej.
Żeby jednak nie powtarzać wiedzy i ze względu na to, że Kubernetesa nie warto ruszać jeśli nie słyszałeś nigdy wcześniej o Dockerze, przed dalszą lekturą zalecam się zapoznać z artykułem o tym jak działa sam Docker:

Jeśli przeczytałeś już artykuł powyżej i wiesz już wszystko o Dockerze to w takim razie teraz...
Zapomnij o Dockerze
Pewnie powiesz: "Zaraz chwila... Ale jak to zapomnij? Pierw kazałeś przeczytać artykuł o Dockerze i teraz mam o nim zapomnieć?".
W sumie tak, no może nie do końca. Ogólnie rzecz biorąc, kilka lat temu Kubernetes korzystał z Dockera. Jednak od wersji 1.24 Kubernetes przestał to robić i oficjalnie już nie wspiera Dockera (Is Your Cluster Ready for v1.24? | Kubernetes).
Czemu Kubernetes przestał wspierać Dockera? Bo nie miało to większego sensu. Docker wbrew temu co można przeczytać na niektórych portalach, samemu nie uruchamia kontenerów. Do uruchomienia kontenerów używa innego narzędzia, które nazywa się Containerd (containerd – An industry-standard container runtime with an emphasis on simplicity, robustness and portability).
Można powiedzieć, że Docker jest nakładką na Containerd, która sprawia, że uruchamianie kontenerów jest szybkie i proste.
Dlatego przed wersją 1.24 Kubernetesa:
Kubernetes przekazywał polecenia do Dockera -> Docker przekazywał polecenia do Containerd -> Containerd operował na kontenerach.
Od wersji 1.24 Kubernetesa:
Kubernetes przekazuje polecenia do Containerd -> Containerd operuje na kontenerach.
Oczywiście jest to bardzo uproszczony obraz, ale myślę, że wystarczający do tego aby zrozumieć wcześniejsze zależności z Dockerem.
Ale po co mi właściwie Kubernetes?
Sam Docker został stworzony głównie z myślą o programistach. Aplikacja umieszczona w kontenerze zadziała na każdym komputerze i to jest jedna z mocnych stron tego rozwiązania. Aplikację umieszczoną w Dockerze możemy przekazać innej osobie bez obaw o to, czy dana osoba ma na komputerze zainstalowane odpowiednie zależności, bo wiemy, że wszystko co potrzebne już jest obecne w kontenerze. Mamy więc pewność, że aplikacja zadziała zawsze, na każdym systemie z zainstalowanym jedynie Dockerem.
Takie rozwiązanie może wydawać się bardzo kuszące jeżeli chodzi o środowiska produkcyjne. W końcu nie musimy się martwić, czy nasza aplikacja zadziała w tak często stresującym momencie, którym jest wdrażanie aplikacji na produkcję. I co ciekawe Docker często jest również właśnie w taki sposób wykorzystywany.
Jednak pomimo tego, że Docker wiele spraw ułatwia, w większym środowisku produkcyjnym może być problematyczny w utrzymaniu. Żeby jednak lepiej to wyjaśnić, posłużę się przykładem.
Krótka Historia pewnej aplikacji
Załóżmy, że masz napisaną aplikację, która została umieszczona w kontenerze Dockerowym. Coś bardzo prostego, jakaś aplikacja napisana w PHP. Postanawiasz, że kupisz serwer, postawisz na tym jakiegoś Linuxa, zainstalujesz Dockera i opublikujesz stronę w internecie.
Strona okazuje się sukcesem, klientów przybywa i Twój serwer powoli niedomaga. Decydujesz się na kupno kolejnego serwera, na którym też instalujesz Dockera. Na pierwszym serwerze instalujesz usługę load balancer typu HAproxy, aby rozłożyć ruch na obu serwerach.
Sukces aplikacji jednak jest tak duży, że z czasem i drugi serwer zaczyna Ci nie wystarczać, dlatego dokładasz kolejne serwery i kolejne... Na każdym instalujesz Dockera i swoją aplikację. Każdy serwer dodajesz do backendu w HAproxy.
Aż w końcu kiedy dodajesz już 20 serwer uświadamiasz sobie, że trzeba zaktualizować aplikację. Dlatego logujesz się na każdy serwer i uruchamiasz nową wersję aplikacji w Dockerze. Żeby klienci nie odczuli zmian, przed aktualizacją każdego z serwerów, po kolei zatrzymujesz na HAproxy ruch do obecnie aktualizowanego serwera.
Niestety, okazuje się, że nowa wersja aplikacji ma błąd i szybko musisz wrócić do poprzedniej wersji. Dlatego znowu logujesz się na każdy serwer i przywracasz poprzednią wersję.
Żeby temu zaradzić na następny raz automatyzujesz sobie wdrażanie aplikacji pisząc odpowiedni Playbook do Ansible.
Pewnego dnia z jakiegoś powodu pierwszy serwer, na którym jest HAproxy, ulega uszkodzeniu. Aplikacja przestaje działać. Po jakimś czasie udaje Ci się ożywić serwer, ale klienci są niepocieszeni.
Żeby się przed tym uchronić na następny raz, postanawiasz zrobić drugi serwer z HAproxy i tworzysz pływający pomiędzy load balancerami adres IP, aby utrzymać usługę ciągle aktywną nawet w przypadku awarii.
Po tym incydencie napotykasz kolejny problem, szał na Twoją aplikację minął, jest już mniej eksploatowana i serwery się nudzą. Żeby zminimalizować koszty, rezygnujesz z kilku serwerów. Znowu wdrażasz odpowiednie zmiany w konfiguracji tym razem już na dwóch serwerach z HAproxy.
Po odłączeniu serwerów okazuje się, że jednak źle obliczyłeś obecne zużycie i zrezygnowałeś ze zbyt dużej liczby serwerów, więc znowu dokupujesz kilka serwerów, znowu instalujesz na nich Dockera, wgrywasz aplikację i znowu dodajesz serwery do konfiguracji w HAproxy.
Po jakimś czasie masz pomysł na inną aplikację, którą postanawiasz wrzucić na kilka serwerów jednak szybko okazuje się, że serwery z zainstalowanymi dwoma aplikacjami jednocześnie niedomagają. Postanawiasz więc, że jedna część serwerów będzie obsługiwać jedną aplikację, a druga część drugą aplikację.
W głowie masz już jednak pomysł na trzecią, niewielką aplikację i żeby sobie ułatwić sprawę, zatrudniasz kolejnych administratorów, żeby wdrożenia robiło kilka osób.
Niestety przy wdrożeniu trzeciej aplikacji na istniejące już serwery z poprzednimi aplikacjami, zaczynają szwankować dwie pierwsze, ze względu na to, że nowy administrator popełnił przypadkiem jakiś błąd.
Żeby temu zaradzić, ograniczasz dostęp dla innych administratorów do części serwerów i nowe osoby wykonują wdrożenia tylko na specjalnie wydzielonych do tego celu serwerach.
Podsumujmy. Żeby środowisko oparte o Dockery bez orkiestracji działało bez problemów przy dużej ilości serwerów, zarządzanych przez kilku administratorów, musisz samemu, za pomocą różnych odpowiednich technologii zadbać o:
- odporność na awarię
- automatyzację wdrożeń aplikacji ze strategią zachowania 100% dostępności
- równoważenie ruchu i ewentualną migrację kontenerów
- monitoring każdego serwera pod względem zużycia zasobów
- ograniczanie dostępu do serwerów
I oczywiście wszystkie powyższe problemy można rozwiązać na kilka sposobów jednak...
Czy można prościej?
Oczywiście, i właśnie po to jest Kubernetes. Klaster Kubernetes:
- Ma wbudowane mechanizmy, które odpowiadają za odporność na awarie (sprzętową jak i również awarię aplikacji w kontenerze)
- Ma API, dzięki czemu wdrożenie aplikacji jest wykonywane poprzez połączenie do jednego API, które łączy wszystkie serwery połączone w jeden klaster Kubernetesa
- Ma wbudowane mechnizmy do równoważenia obciążenia i automatycznej migracji kontenerów
- Ma wbudowany monitoring (w tym monitoring obciążenia) oraz mechanizmy logowania błędów
- Każde wdrożenie może mieć swoje wydzielone miejsce (namespace), z ograniczonym dostępem oraz zasobami, bez konieczności ograniczania go do konkretnych maszyn
W porządku, ale jak to działa?
Najczęściej w tym momencie wielu zaczyna tłumaczyć Ci czym są terminy takie jak: pod, service, ingress, deployment, daemonset, replicaset, persistent volume, persistent volume claim, horizontal pod autoscaler i... inne.
Oczywiście warto znać te terminy, jednak uważam, że zaczynanie nauki od studiowania definicji każdego z powyższych elementów, może zniechęcić do dalszego zdobywania wiedzy. Tak naprawdę, aby zrozumieć jak działa Kubernetes, najlepiej go po prostu użyć do czegoś prostego w praktyce.
Problem w tym, że jeśli chcemy użyć Kubernetesa w praktyce, korzystając z narzędzia kubectl i tak potrzebujemy znać powyższe terminy.

Poza tym, tworzenie nowych wdrożeń w Kubernetesie, zwykle wiąże się z pisaniem tak zwanych manifestów, czyli zestawu poleceń, które Kubernetes ma dla nas wykonać co dla niektórych może wydawać się ścianą nie do przeskoczenia.
Dlatego, żeby było prościej, posłużymy się czytelnym i łatwym w obsłudze Rancherem.
Czym jest Rancher?
Krótko mówiąc jest to bardzo zaawansowany i popularny panel do zarządzania klastrami Kubernetesa.
Z uwagi na bardzo prosty i przejrzysty interfejs, Rancher jest bardzo łatwy w użyciu. Poza tym jest darmowy i co najlepsze, Rancher potrafi napisać manifesty za nas. Użytkownik musi jedynie wpisać odpowiednie dane w bardzo prostym w użyciu formularzu.
Ciekawostką jest to, że Rancher działa w Kubernetesie. Postaram się jednak ułatwić proces instalacji lokalnego klastra Kubernetes oraz Ranchera do minimum.
Instalacja K3s i Ranchera
Rancher nie należy do najlżejszych, dlatego komputer na którym go uruchomimy, najlepiej żeby miał przynajmniej 16 GB RAM. Osobiście uruchomiłem go bez problemu na Surface Pro 8 na CPU i5 11 generacji od Intela i 16 GB RAM. Nie zalecam instalacji Ranchera w ten sposób przy mniejszej ilości dostępnej pamięci.
Jednak jeśli twój komputer ma mniejszą ilość pamięci, nadal możesz nauczyć się z tego poradnika jak zainstalować K3S w WSL v2 (i ewentualnie na własną rękę zainstalować coś lżejszego, np. Kubernetes Dashboard).
Czym jednak jest K3S? Jest to lekka ale jednocześnie bardzo potężna dystrybucja Kubernetesa. Jest bardzo prosta w instalacji i świetnie sprawdzi się w ewentualnym wysoko dostępnym środowisku produkcyjnym.
Statystycznie rzecz biorąc, większość osób korzysta z Windowsa, dlatego pokażę, jak zainstalować Ranchera używając:
Windows -> WSL (z systemem AlmaLinux 9) -> K3S
WSL (Windows Subsystem for Linux) pozwoli nam na szybką instalację lekkiego Linuxa, na którym będziemy mogli eksperymentować.
Oczywiście nic nie stoi na przeszkodzie, aby uruchomić inną dystrybucję Linuxa na VirtualBoxie, Hyper-V, Proxmoxie czy Vmware, a następnie na niej K3S. Jednak w tym poradniku użyjemy WSL v2 ponieważ wydaje się najwygodniejszą i najszybszą opcją.
Instalację WSL dla Windows 10 i 11 można znaleźć tutaj (będzie to niezbędne aby przejść dalej):

Jeśli masz już WSL, możemy zainstalować tam Linuxa. Osobiście proponuję AlmaLinux 9, który znajdziesz w Microsoft Store:
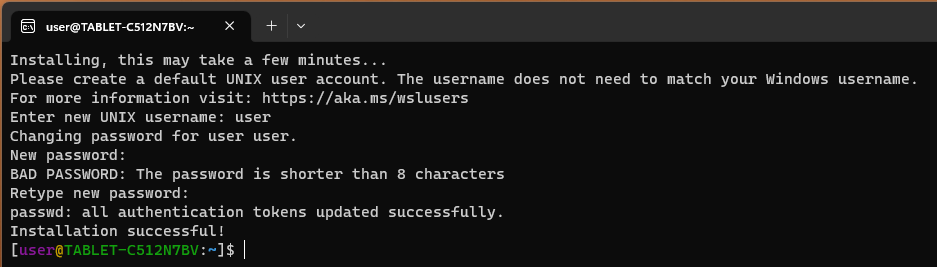
Po zainstalowaniu naszego nowego Linuxa pod WSL, uruchamiamy go i tworzymy nowego użytkownika:
Domyślnie, Linux uruchomiony w WSL nie obsługuje systemd, które jest potrzebne do instalacji K3S. Dlatego, żeby uruchomić systemd, musimy jako root edytować plik /etc/wsl.conf i dodać do niego następujące linie:
[boot]
systemd=true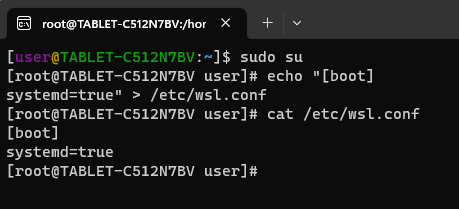
Żeby powyższa zmiana została zastosowana w Linuxie, musimy go zrestartować. W tym celu zamykamy kartę z naszym Linuxem i otwieramy kartę z PowerShellem w którym uruchamiamy polecenie wsl --shutdown:
To polecenie zamyka wszystkie systemy uruchomione w WSL.
Teraz możemy ponownie uruchomić kartę z AlmaLinuxem i sprawdzić czy systemd działa prawidłowo:
Kiedy mamy już gotowy system do instalacji Kubernetesa, jako root uruchamiamy polecenie:
curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION=v1.26.9+k3s1 sh -s - server --cluster-init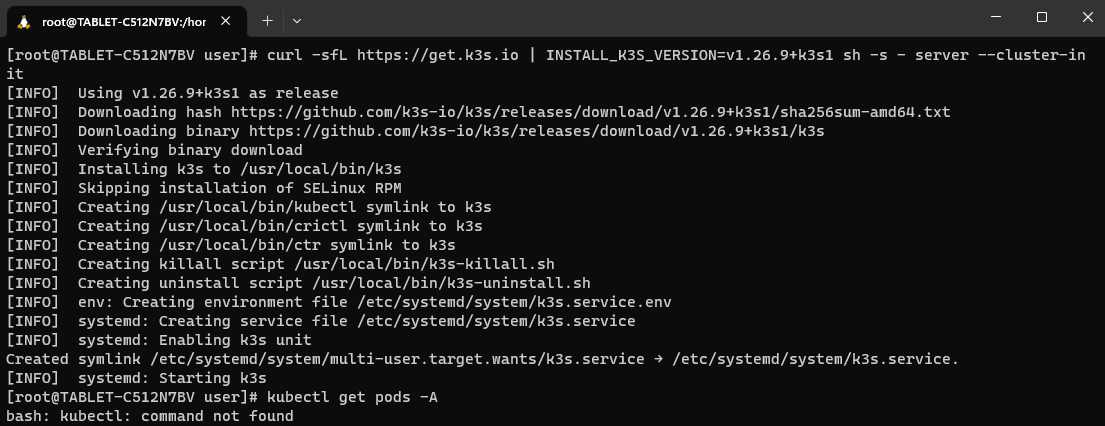
Jak widzimy, skrypt instalacyjny umieścił kilka plików w /usr/local/bin/. Dlatego dla ułatwienia dodajemy tę ścieżkę do PATH poleceniem:
export PATH=$PATH:/usr/local/binŻeby przy każdym uruchomieniu terminala nie musieć za każdym razem wykonywać tego polecenia, warto dodać je na końcu pliku /root/.bashrc.
Teraz powinniśmy mieć możliwość używania poleceń kubectl:
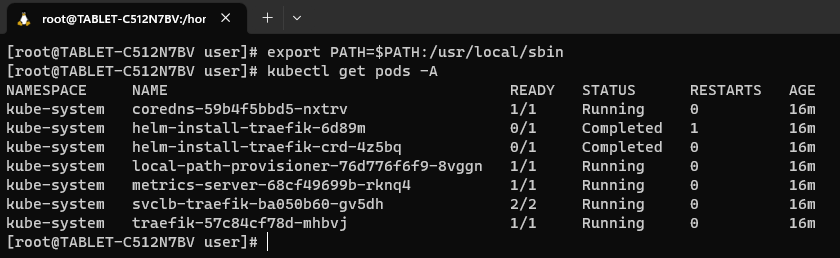
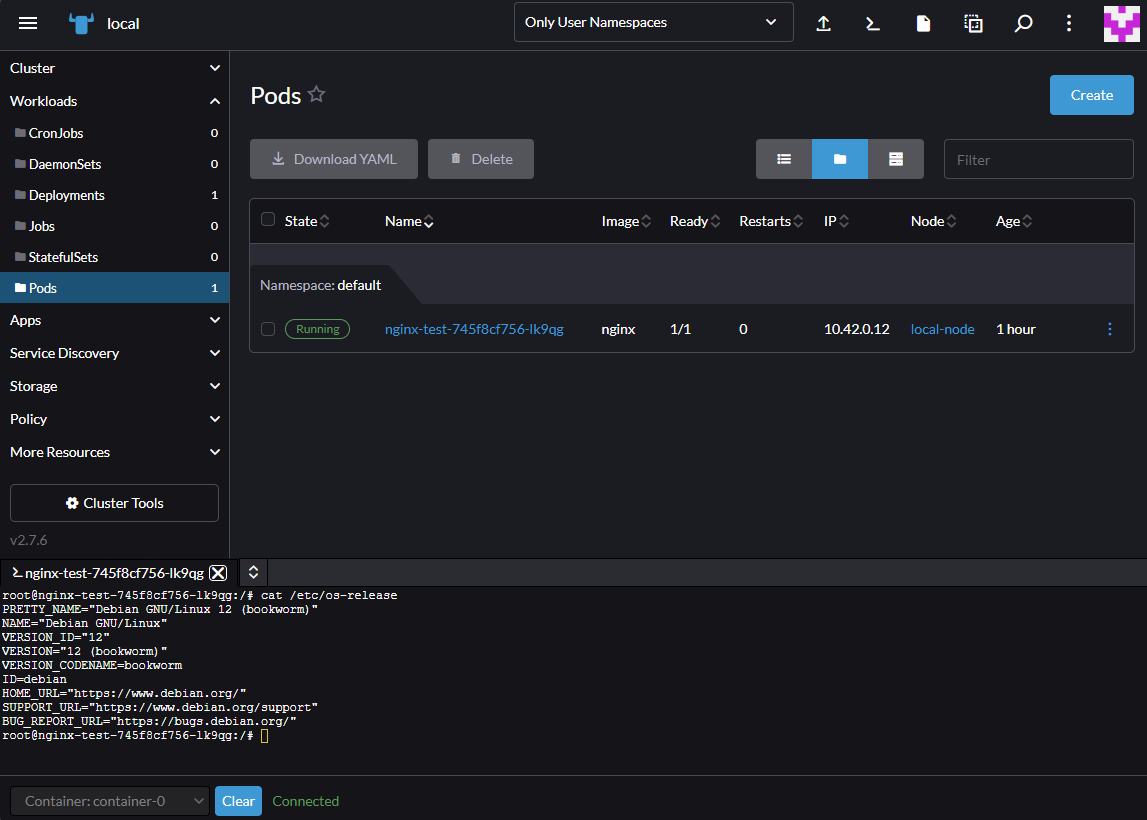
Nasz w pełni funkcjonalny Kubernetes jest już gotowy. Powyżej widzimy listę Podów w Namespace o nazwie kube-system, odpowiedzialnych za działanie Kubernetesa.
Tutaj możemy się na chwilę zatrzymać aby wytłumaczyć kilka terminów.
Pody to w zasadzie kontenery, w których są uruchomione aplikacje. Dlaczego więc nazywa się to Pod zamiast po prostu kontener? Przede wszystkim dlatego, że jeden Pod może zawierać w sobie więcej niż jeden kontener. Poza tym Pod oprócz tego, że zawiera w sobie kontenery, ma również logikę, która na przykład sprawdza czy kontener w Podzie jest aktywny. Pod pomimo tego że może zawierać kilka kontenerów, zawsze ma jeden adres IP, które kontenery wewnątrz współdzielą. Na powyższym zrzucie ekranu widzimy między innymi uruchomione Pody:
- coredns - wewnętrzna usługa DNS służąca do komunikacji pomiędzy Podami w sieci Kubernetesa
- metrics-server - serwer metryk zbierający dane o zużyciu CPU i pamięci przez kontenery. Potrzebny do działania polecenia kubectl top node czy autoskalowania.
- traefik - krótko mówiąc jest to proxy, które w nomenklaturze Kubernetesa nazywane jest Ingress Controllerem. Żeby zrozumieć jak działa posłużmy się przykładem bardzo popularnego serwera WWW, czyli Apache. W Apache tworzymy VirtualHosty (czyli jeszcze inaczej: podpięte domeny w np. cPanel), żeby przekierować użytkownika po wykrytej nazwie domenowej na jakiś plik lub inny serwer. W Kubernetesie tworzymy Ingressy aby przekierować użytkownika po wykrytej nazwie domenowej na daną usługę (Service), która końcowo, przekieruje nas na jakiś Pod.
Z kolei Namespace to przestrzeń w której tworzone są Pody. Możemy tworzyć kilka Namespace'ów, żeby uporządkować nasze Pody. Poza tym, jeśli chcemy na przykład, komuś udostępnić klaster Kubernetes, możemy ograniczyć dostęp do jednego Namespace, w którym ktoś będzie mógł wykonać deploy swojej aplikacji.
Wróćmy jednak do instalacji panelu Rancher. Przed instalacją potrzebujemy przygotować jakąś domenę, którą przekierujemy na IP naszego Linuxa. Żeby jednak poznać IP Linuxa uruchomionego w WSL, potrzebujemy zainstalować pakiet hostname:
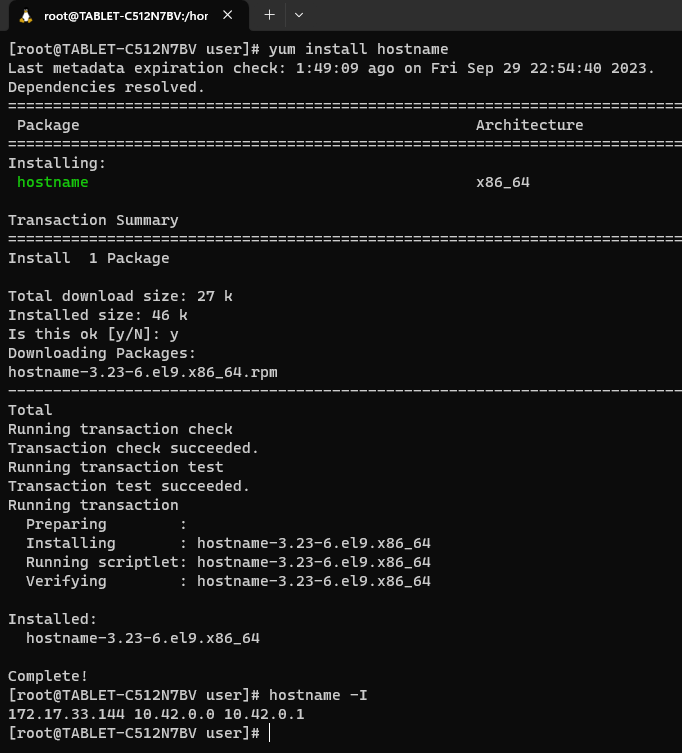
Jak widać powyżej, po zainstalowaniu pakietu hostname i wykonaniu polecenia hostname -I możemy zobaczyć adres IP systemu uruchomionego w WSL (adres pierwszy od lewej).
Teraz uruchamiamy w Windowsie uruchamiamy notatnik jako administrator i edytujemy plik /etc/hosts
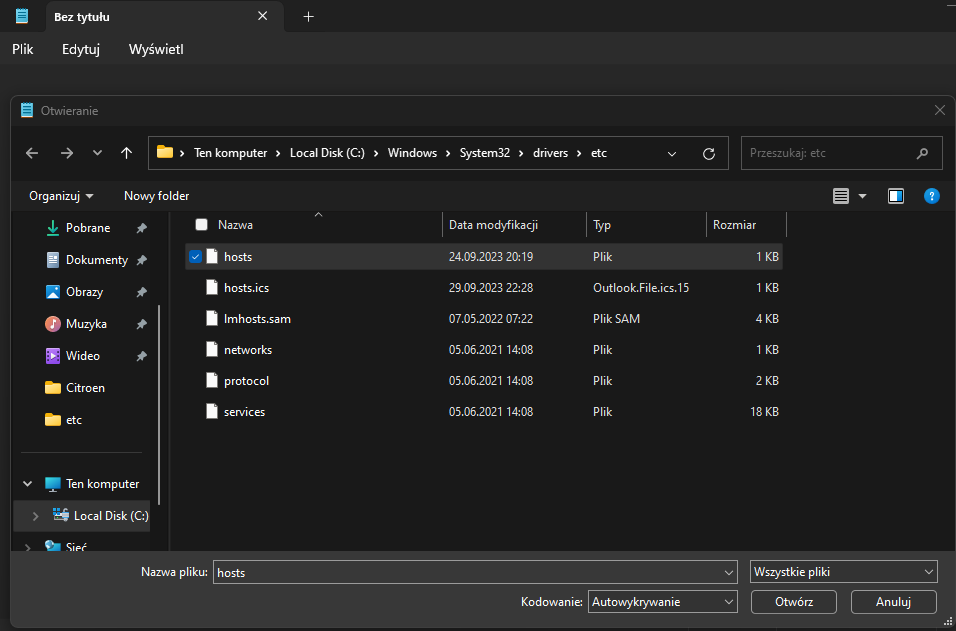
Po otwarciu tego pliku, dodajemy domenę np. rancher.local, którą przekierowujemy na adres IP Linuxa uruchomionego w WSL i zapisujemy plik
Teraz prawie jesteśmy gotowi do instalacji Ranchera. Prawie ponieważ będziemy potrzebować jeszcze narzędzia Helm.
Helm jest menedżerem pakietów. Jest to taki trochę yum/dnf/apt/zypper tylko dla Kubernetesa.
Żeby zainstalować Helma, wystarczy wykonać polecenie:
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
Teraz mamy wszystko gotowe do tego, aby zainstalować Ranchera.
Dlatego teraz wykonujemy po kolei poniższe polecenia:
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
helm repo add rancher-latest https://releases.rancher.com/server-charts/latest
kubectl create namespace cattle-system
kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.11.0/cert-manager.crds.yaml
helm repo add jetstack https://charts.jetstack.io
helm repo update
helm install cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.11.0
helm install rancher rancher-latest/rancher \
--namespace cattle-system \
--set hostname=rancher.local \
--set replicas=1 \
--set bootstrapPassword=Haslo_do_panelu_rancherPo wykonaniu ostatniego polecenia, powinien przywitać nas następujący komunikat:
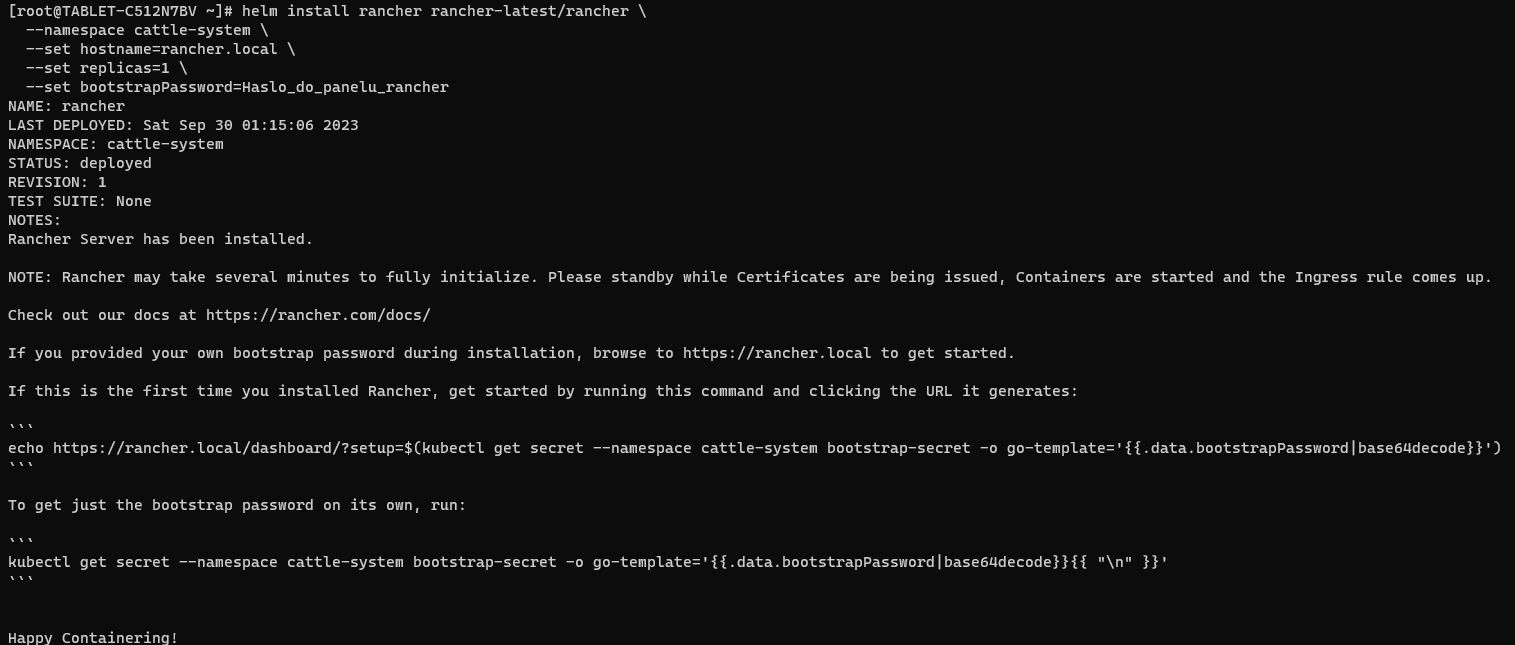
Teraz wykonując polecenie:
echo https://rancher.local/dashboard/?setup=$(kubectl get secret --namespace cattle-system bootstrap-secret -o go-template='{{.data.bootstrapPassword|base64decode}}')Otrzymamy adres, którym możemy zalogować się do naszego panelu Rancher. Po uruchomieniu tego adresu IP w przeglądarce, powinien ukazać się nam komunikat o nieprawidłowym certyfikacie (który oczywiście pomijamy), a następnie panel Rancher:
Akceptujemy licencję i przechodzimy dalej.
Gotowe! Rancher jest gotowy do zarządzania naszym Kubernetesem.
Teraz klikamy na nazwę naszego klastra (local) i możemy zaczynać naszą zabawę z Kubernetesem.
Tworzymy pierwszy Deployment
Kiedy mamy już postawiony panel Rancher, możemy w prosty sposób spróbować coś umieścić w klastrze Kubernetes.
Dla przykładu spróbujemy na naszym klastrze Kubernetes uruchomić... WordPressa.
Jednak, żeby uruchomić WordPressa, potrzebujemy bazy danych MySQL. Oczywiście moglibyśmy zainstalować MySQL na naszym Linuxie, ale po co skoro w prosty i szybki sposób, możemy uruchomić ją na naszym Kubernetesie.
W tym celu przechodzimy do zakładki Workloads -> Deployments, a następnie klikamy Create.
W polu Name wpisujemy np. mariadb, a następnie w polu Container image wpisujemy mariadb. W polu Container image istotne, żebyśmy nie zrobili literówki, ponieważ tutaj decydujemy, jaki obraz ma zostać pobrany.
Przy tym polu warto też dodać, że możemy w nim wpisać nazwę dowolnego obrazu dostępnego w Docker Hub
Teraz musimy sprawić, aby nasz MySQL był dostępny w sieci klastra Kubernetes. W tym celu w sekcji Networking dodajemy Service typu Cluster IP o nazwie mariadb, i Private Container Port ustawiamy na 3306.
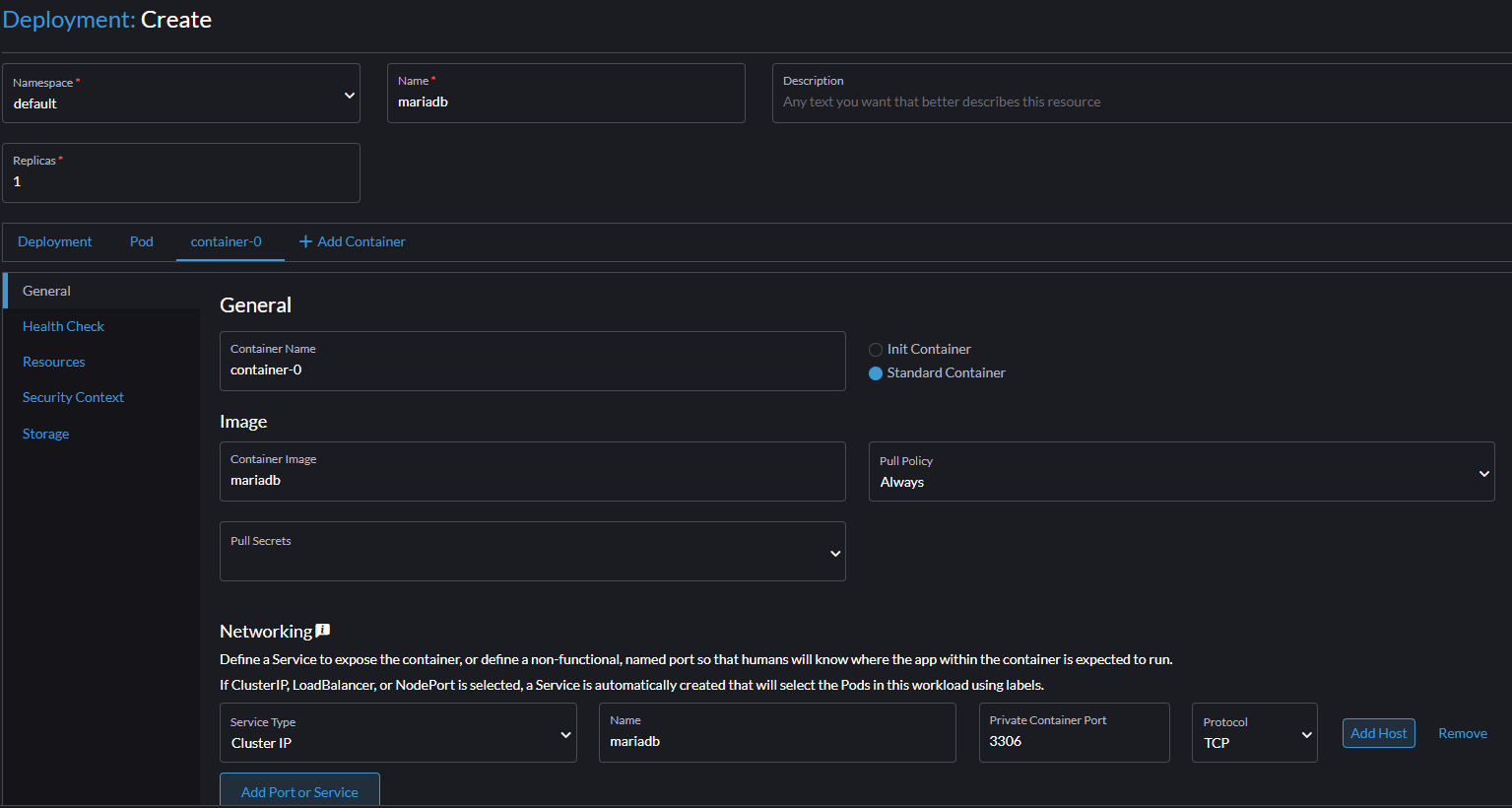
Teraz schodzimy niżej do sekcji Environment Variables i dodajemy następujące zmienne typu Key/Value Pair (zgodnie z dokumentacją Docker Hub):
MARIADB_RANDOM_ROOT_PASSWORD = 1
MARIADB_USER = wordpress
MARIADB_PASSWORD = password
MARIADB_DATABASE = wordpressCałość będzie wyglądać następująco:
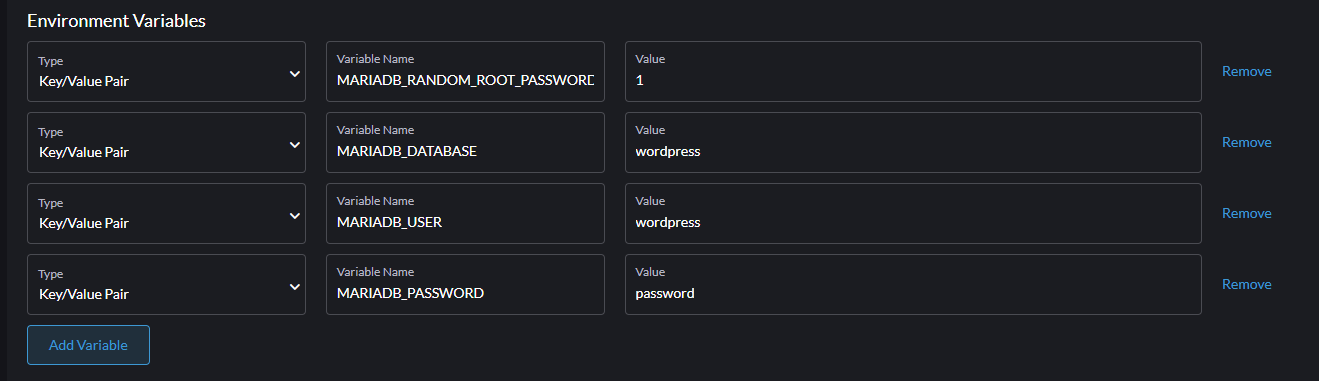
Po wypełnieniu powyższych pul, klikamy Create.

Jeśli wszystko wypełniliśmy prawidłowo, nasz kontener z MySQL powinien być aktywny.
Jeśli chcemy dla zabawy wejść do utworzonego kontenera, możemy kliknąć 3 kropki po prawej stronie i wybrać Execute Shell.
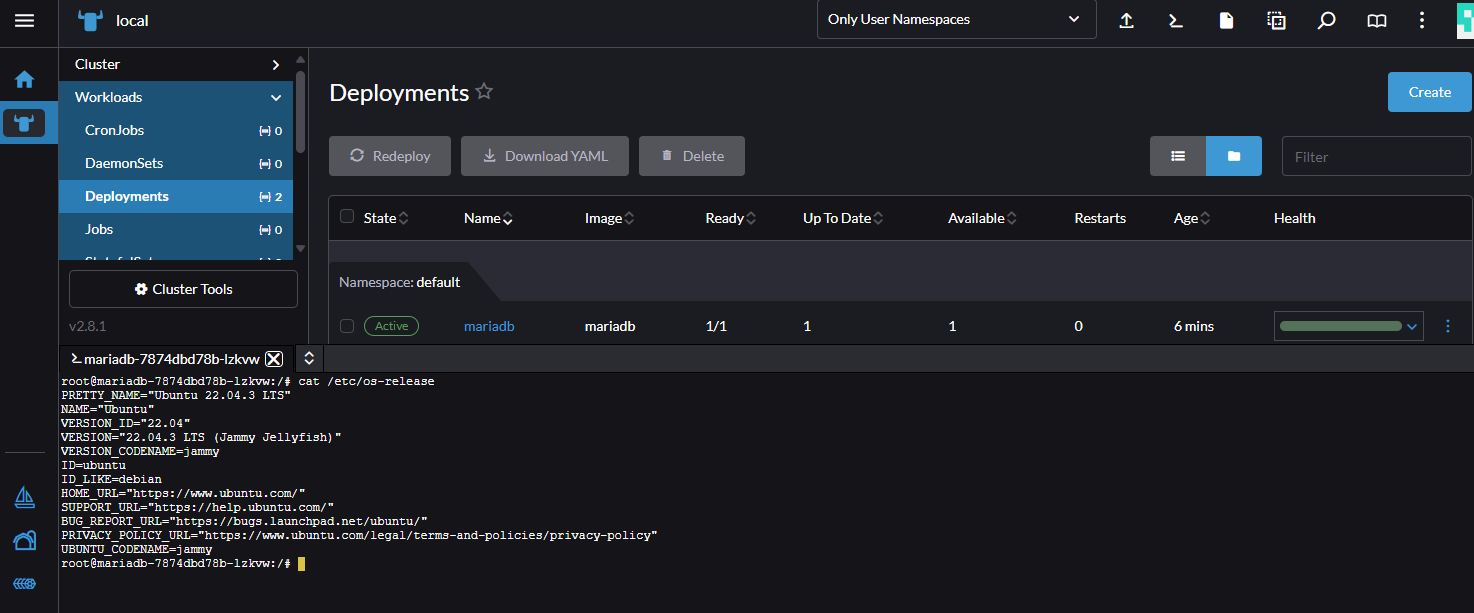
Skoro nasza baza danych jest już gotowa, możemy teraz uruchomić naszego WordPressa. Żeby to zrobić, tworzymy kolejny Deployment.
Tym razem w polu Name wpisujemy np. wordpress, następnie w polu Container image wpisujemy wordpress.
Następnie w sekcji Networking dodajemy Service typu Node Port o nazwie wordpress. Private Container Port ustawiamy na 80, z kolei Listening Port ustawiamy na 30001.
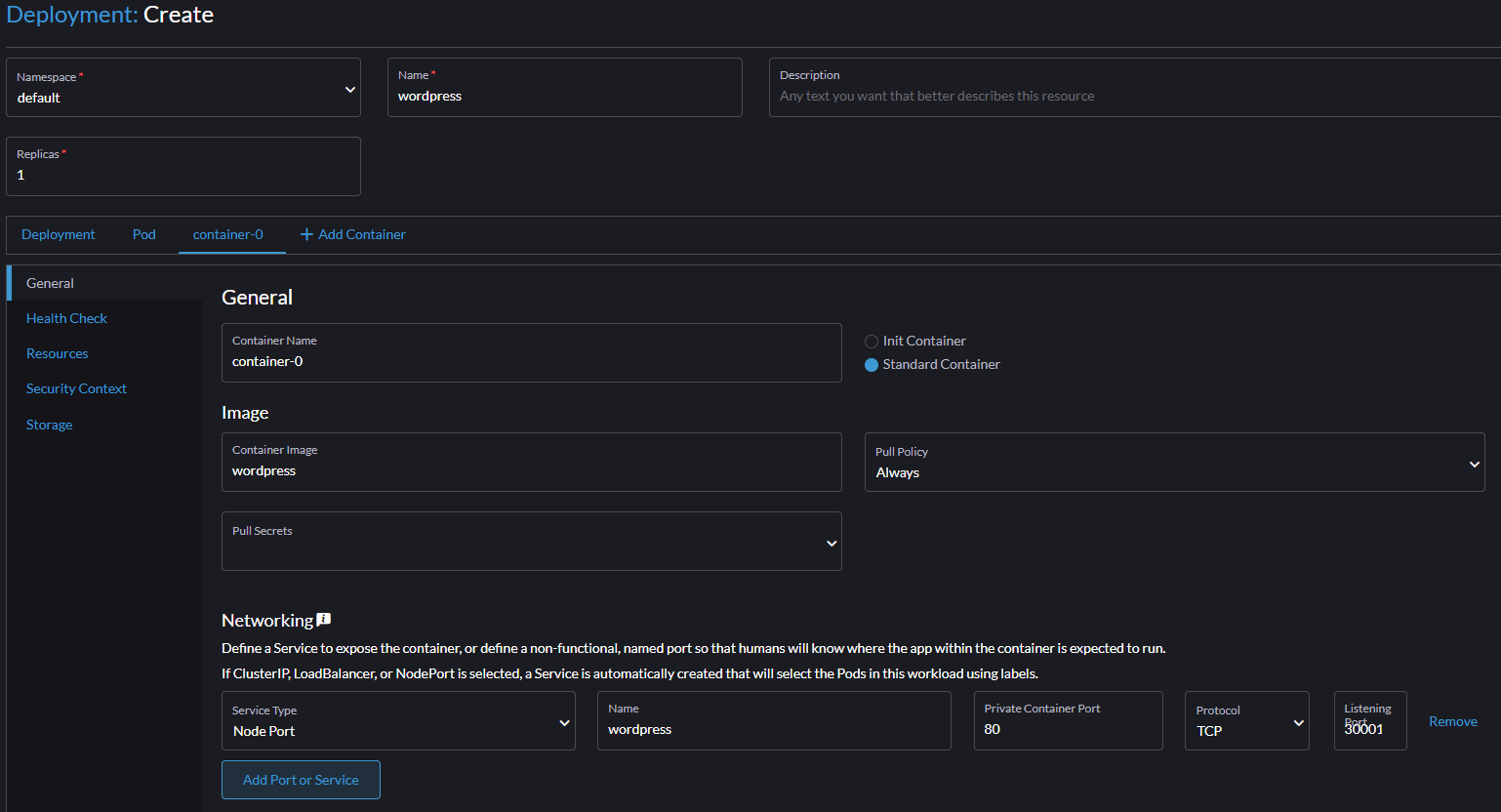
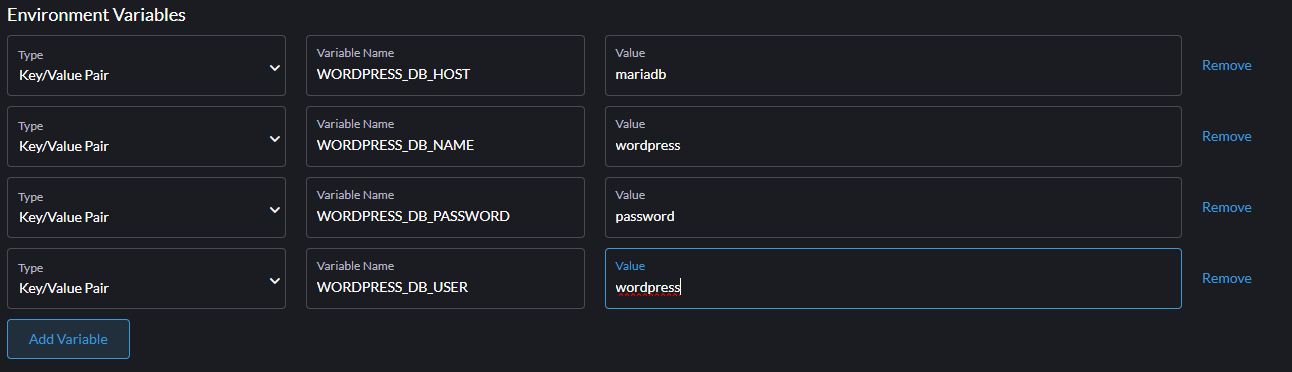
Teraz schodzimy niżej do sekcji Environment Variables i dodajemy następujące zmienne typu Key/Value Pair:
WORDPRESS_DB_HOST = mariadb
WORDPRESS_DB_USER = wordpress
WORDPRESS_DB_PASSWORD = password
WORDPRESS_DB_NAME = wordpressTutaj warto się zatrzymać przy zmiennej WORDPRESS_DB_HOST. Tutaj w standardowej instalacji np. na hostingu współdzielonym, podalibyśmy IP lub nazwę domenową serwera MySQL.
Jednak w Kubernetesie, musimy podać nazwę stworzonego Service, kierującego na Pod z serwerem MySQL. W naszym przypadku Service nazywa się po prostu mariadb. Jednak jeśli nie wiedzielibyśmy jaką nazwę ma nasz Service, można to sprawdzić w zakładce Service Discovery -> Services
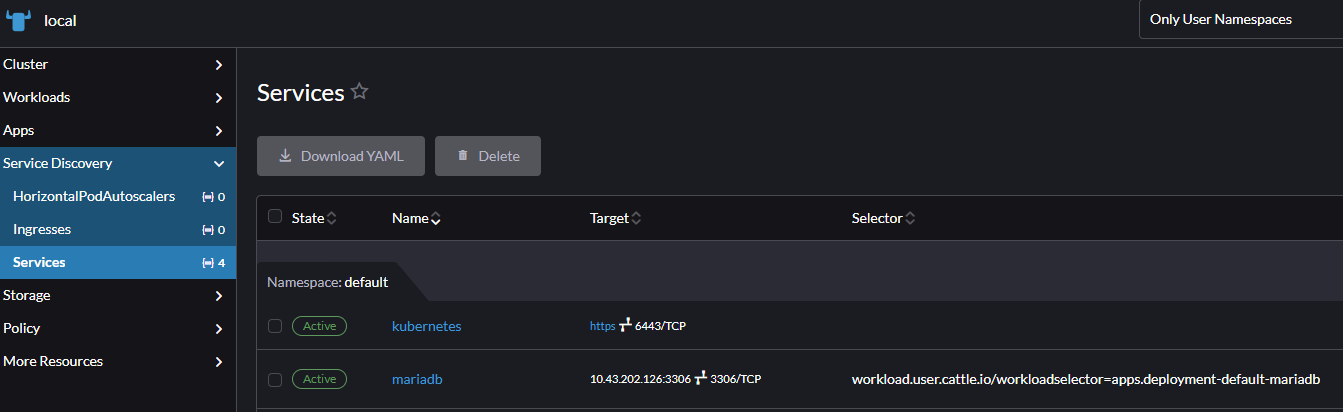
Całość będzie więc wyglądać następująco:
Klikamy Create i po kilku chwilach powinniśmy zobaczyć taki oto widok:
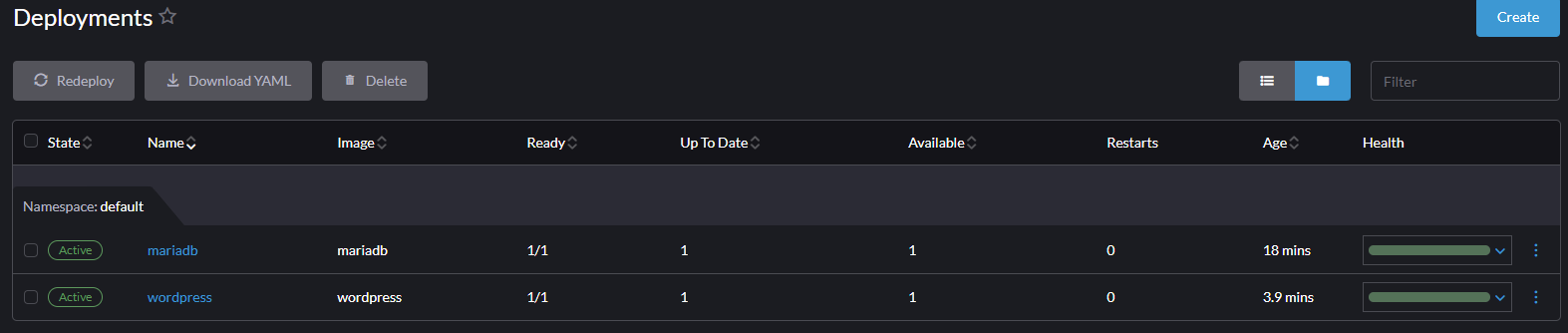
W porządku, kontenery działają. Ale co z naszym WordPressem?
Otóż wystawiliśmy go na porcie 30001. Wchodzimy więc pod adres:
http://rancher.local:30001
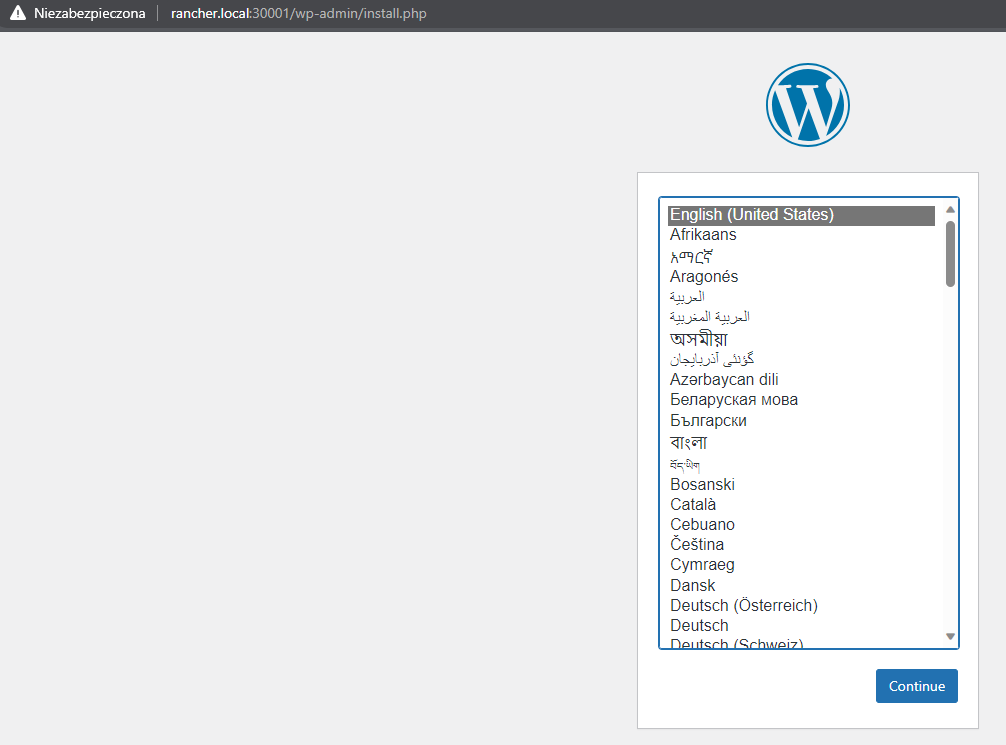
Jeśli wszystko zrobiliśmy prawidłowo, powinniśmy ujrzeć instalator Wordpressa:
Prawda, że to było proste?
No tak, ale co my właściwie zrobiliśmy?
- Utworzyliśmy Deployment, który utworzył nam Pod z kontenerem zwierającym MySQL, oraz Service nasłuchujący na porcie 3306 w sieci klastra Kubernetes (Cluster IP) i kierujący na ten Pod.
- Utworzyliśmy drugi Deployment, który utworzył nam Pod z kontenerem zawierającym WordPressa, oraz Service typu Node Port nasłuchujący na zewnątrz na porcie 30001 i kierujący na ten Pod.
Gdybym napisałbym to na początku, można by było uznać powyższe słowa za jakąś czarną magię. Jednak użycie odpowiedniego narzędzia potrafi zmienić perspektywę.
Kiedy mamy już gotowy Deployment z WordPressem, zobaczmy jeszcze jak w bardzo prosty sposób, możemy skalować naszą aplikację.
Żeby to zrobić wystarczy, że w zakładce Health klikniemy strzałkę w dół, a następnie klikniemy znak +
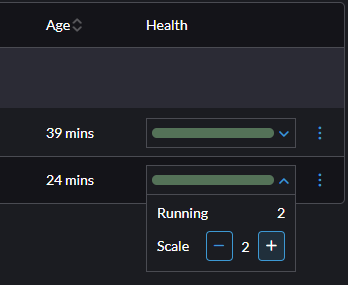
Po kilku chwilach powinien się pojawić kolejny kontener z naszym WordPressem.
Możemy to zobaczyć w zakładce Workloads -> Pods
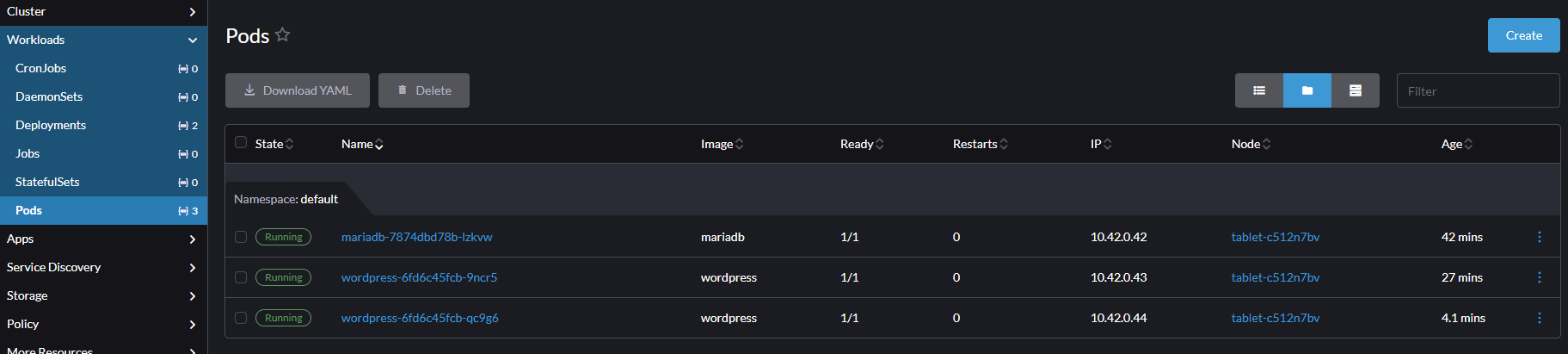
Teraz ruch na stronie http://rancher.local:30001 będzie rozłożony jednocześnie na dwóch kontenerach. Możesz oczywiście utworzyć więcej Podów, jeśli Twój komputer to udźwignie.
Przy skalowaniu ciekawą rzeczą, która może wydawać się nieintuicyjna jest to, że gdy spróbujesz usunąć dany Pod, zaraz po jego usunięciu na jego miejsce pojawi się drugi. Odpowiada za to tak zwany ReplicaSet jednak to już jest materiał na inny artykuł 😊
Podsumowanie
Jak widzisz, używając odpowiednich narzędzi, utworzenie czegoś w klastrze i zarządzanie klastrem Kubernetes nie musi być trudne.
Oczywiście to co opisałem wyżej to zaledwie kropla tego, co możemy zrobić w Kubernetesie. Na Kubernetesie złożonym z jednej maszyny, nie możemy w praktyce doświadczyć potęgi tego rozwiązania. Potraktuj jednak ten artykuł jako taki całkowicie podstawowy wstęp do nauki tej technologii.
Narzędzia takie jak K3S i Rancher skutecznie pozwalają pokonać stromą krzywą uczenia się Kubernetesa, a jednocześnie często są używane w środowiskach produkcyjnych, dlatego na pewno warto je znać.
Na koniec zachęcam Cię do eksperymentowania z Kubernetesem w panelu Rancher i próbowania różnych konfiguracji i obrazów kontenerów.
Mam nadzieję, że chociaż trochę pomogłem Ci się oswoić z tą technologią oraz oczywiście życzę powodzenia w nauce Kubernetesa 😊



