

Docker jest przydatnym narzędziem służącym do wirtualizacji na poziomie systemu operacyjnego. Oprogramowanie to pozwala na uruchamianie procesów aplikacji w "lekkich" kontenerach odizolowanych od systemu operacyjnego hosta. W pewnym sensie kontenery przypominają maszyny wirtualne jednak zakres izolacji obsługiwany przez dockera jest zdecydowanie mniejszy.
Kontenery w przeciwieństwie do maszyn wirtualnych korzystają z tego samego jądra a izolacja jest zaimplementowana w ramach tego pojedynczego jądra. Nazywamy to wirtualizacją systemu operacyjnego. Z kolei maszyny wirtualne są ciężkie i zasobożerne w porównaniu do kontenerów z uwagi na fakt, iż każda ich nowa instancja jest równoznaczna z nową instancją jądra.
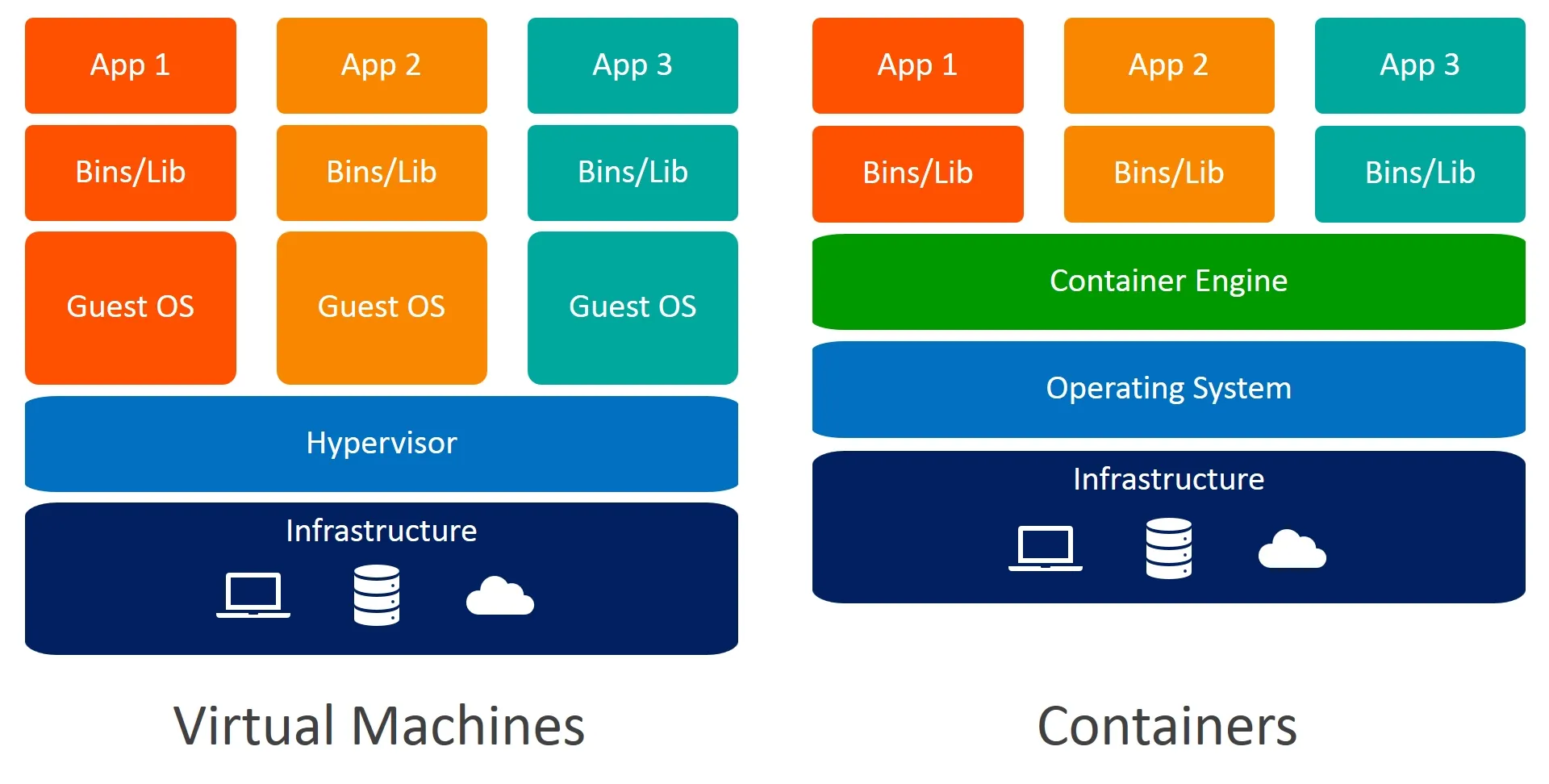
Wymienione technologie tj. wirtualizacja i konteneryzacja są nieco odmienne w związku z tym ich zastosowanie będzie również nieco inne.
Maszyny wirtualne wykorzystamy gdy chcemy mieć pełną izolację od systemu operacyjnego hosta jak również mając potrzebę uruchomienia wielu różnych systemów operacyjnych na tym samym komputerze. Maszyny wirtualne z założenia zastępują rzeczywisty sprzęt, który można postawić w szafie na kilka lat. Ponieważ zastępują one prawdziwy serwer często z założenia są utrzymywane przez długi czas.
Kontenery wykorzystamy gdy chcemy uruchamiać nasze aplikacje w "lekkich opakowaniach" w sytuacjach gdy tworzenie kolejnej maszyny wirtualnej byłoby zbyt kosztowne. Przykładowo nie uruchomilibyśmy maszyny wirtualnej aby wystartować w niej pojedynczy proces np. curl albo ffmpeg w celu uzyskania wyniku ponieważ byłoby to bardzo czasochłonne i wymagałoby uruchomienia całego systemu operacyjnego w celu wykonania jednego polecenia. Kontenery natomiast idealnie nadają się do tego typu zastosowań a jedną z największych korzyści z ich zastosowania jest dobre wykorzystanie zasobów ponieważ nie jest potrzebny cały system operacyjny dla każdej wyizolowanej funkcji. Kontenery również znajdą zastosowanie do szybkiego stawiania lokalnych środowisk np. przy użyciu Docker Compose.
Jednak być może zastanawiasz się w jakim celu pakować swoje aplikacje w kontenery? Po co jest ta kolejna warstwa? Czemu nie instalować aplikacji bezpośrednio na serwerze? Przecież Java już wykonuje się na maszynie wirtualnej po co więc ta kolejna abstrakcja?
Jedną z najważniejszych silnych stron dockera jest jego zdolność do odseparowania aplikacji od sprzętu i systemu operacyjnego serwera, na którym działa dzięki czemu Twoja aplikacja nie jest przywiązana do żadnego konkretnego komputera czy środowiska. Z dockerem dostarczasz aplikację wraz ze wszystkimi plikami niezbędnymi do jej uruchomienia w postaci obrazu lub artefaktu, z którego później tworzone są działające kontenery. W celu wdrożenia aplikacji na dane środowisko nie musisz na nim instalować zależności czy też bibliotek, od których aplikacja zależy ponieważ wszystkie zależności są już w środku w obrazie. Pozwala to nie tylko horyzontalnie skalować aplikacje w prosty sposób używając różnych platform do orkiestracji np. Kubernetes lub Swarm, ale również uniknąć dziwnych błędów spowodowanych różnicami w konfiguracji między środowiskami ponieważ aplikacja nie zależy od zewnętrznego środowiska.
Architektura
W dużym uproszczeniu Docker składa się z trzech komponentów:
- docker - klient serwera czyli warstwa, z którą użytkownik końcowy ma największą styczność
- dockerd - serwer, demon działający w tle, który zarządza kontenerami i obsługuje żądania od klienta
- rejestry - repozytoria, z których Docker zaciąga obrazy np. Docker Hub

Warto wspomnieć, że proces dockerd można uruchomić natywnie tylko w systemie Linux. Jeżeli uruchamiamy Dockera w systemach Windows lub MacOS to wykorzystamy wirtualną maszynę z uruchomionym systemem Linux aby uruchomić dockerd - serwer Dockera.
Każdy kontener powstaje z obrazu podobnie jak wirtualny dysk staje się maszyną wirtualną po jej uruchomieniu. W pracy z Dockerem wykorzystujemy gotowe obrazy pobrane z zdalnego repozytorium lub tworzymy własne z wykorzystaniem pliku Dockerfile.
Plik Dockerfile
Plik, który opisuje wszystkie kroki niezbędne do wykonania aby utworzyć jeden obraz. Zazwyczaj powinien być umieszczony w głównym katalogu repozytorium aplikacji, którą chcemy umieścić w obrazie.
Poniżej przykładowy plik Dockerfile. W komentarzach zawarłem wyjaśnienia poszczególnych komend.
FROM java:8 # obraz bazowy (składa się z wielu warstw tj. obrazów przejściowych)
COPY . /var/www/java # kopiuje bieżący katalog do /var/www/java w kontenerze
WORKDIR /var/www/java # ustawia katalog bieżący w kontenerze
RUN javac Hello.java # uruchamia kompilację programu
CMD ["java", "Hello"] # uruchamia program
Na podstawie tak przygotowanego pliku możemy spróbować zbudować obraz a następnie na jego podstawie uruchomić instancję kontenera.
❯ docker build . -t hello-java
[+] Building 15.4s (10/10) FINISHED
=> [internal] load build definition from Dockerfile
=> [1/4] FROM docker.io/library/java:8@sha256:c1ff613e8ba25833d2e1940da0940c3824f03f802c449f3d1815a66b7f8c0e9d 10.5s
=> => resolve docker.io/library/java:8@sha256:c1ff613e8ba25833d2e1940da0940c3824f03f802c449f3d1815a66b7f8c0e9d 0.0s
=> => sha256:76610ec20bf5892e24cebd4153c7668284aa1d1151b7c3b0c7d50c579aa5ce75 42.50MB / 42.50MB 2.0s
...
=> [2/4] COPY . /var/www/java 0.1s
=> [3/4] WORKDIR /var/www/java 0.0s
=> [4/4] RUN javac Hello.java 2.8s
=> exporting to image 0.0s
=> => exporting layers 0.0s
=> => writing image sha256:e772e4db060862c73991141dc7dc57c7d86655ff2d1685954d865b5debc857c7 0.0s
=> => naming to docker.io/library/hello-java 0.0s
❯ docker run hello-java
Hello world
Obraz dockerowy jest zbudowany z warstw nakładających się na siebie. Każda komenda w pliku Dockerfile dodaje kolejną warstwę. Podczas tego procesu docker uruchamia kontener na bazie obrazu z warstwy niżej następnie wykonuje zadaną operację po czym zapisuje stan systemu plików jako nowy obraz. Ze względu na to, że Docker cache'uje powstałe warstwy aby przyśpieszyć budowanie obrazu, jeżeli dokonamy zmian w pliku Dockerfile i przebudujemy obraz Docker przebuduje tylko te warstwy (obrazy pośrednie), które się zmieniły i wyższe ponieważ wyższe bazują na niższych więc zmiana tych niższych mogła wpłynąć na wyższe warstwy. Z tego względu dobrą praktyką jest umieszczanie jak najniżej pliku poleceń bazujących na zasobach, które często się zmieniają.
Uruchamianie obrazów
Jak widzieliśmy na przykładzie wyżej obrazy uruchamiamy z wykorzystaniem komendy docker run <image>. W ten sposób Docker utworzył na jego podstawie nowy kontener przypisując mu unikalny identyfikator. Za każdym razem gdy uruchomimy docker run stworzymy nową instancję kontenera podobnie jak tworzymy nową instancję klasy za pomocą operatora new w programowaniu obiektowym. Możemy wykonać kilka prostych komend aby przekonać się, że faktycznie tak się dzieje. W tym celu posłużę się obrazem Ubuntu.
❯ docker run ubuntu:latest whoami
root
❯ docker run ubuntu:latest uname -a
Linux 2c410a1519fb 5.10.104-linuxkit #1 SMP PREEMPT Thu Mar 17 17:05:54 UTC 2022 aarch64 aarch64 aarch64 GNU/Linux
❯ docker ps -a | head -3
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2c410a1519fb ubuntu:latest "uname -a" 17 seconds ago Exited (0) 16 seconds ago distracted_napier
89f9a750d6e2 ubuntu:latest "whoami" 26 seconds ago Exited (0) 25 seconds ago nostalgic_yalow
Powyższy test potwierdza, że wykonanie dwóch poleceń używając komendy docker run faktycznie spowodowało stworzenie dwóch różnych kontenerów z unikalnymi identyfikatorami, które zakończyły się po wykonaniu tych poleceń.
Czas życia kontenera jest zdefiniowany przez proces, który jest uruchomiony w środku. Jeżeli proces, który "podtrzymuje" kontener zakończy działanie kontener również się zakończy. Możemy zobaczyć to zachowanie w praktyce używając komendy sleep.
❯ docker run ubuntu:latest sleep 5
Nowa instancja kontenera została stworzona po czym wystartował proces sleep, który zamroził konsolę na 5 sekund następnie proces ten zakończył swoje działanie a zaraz po nim kontener. Zakończony kontener zobaczymy wykonując poniższą komendę, która listuje wszystkie kontenery w systemie.
❯ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4f6d73900753 ubuntu:latest "sleep 5" 13 seconds ago Exited (0) 7 seconds ago
Nie musimy za każdym razem tworzyć nowej instancji kontenera. Możemy wykorzystać polecenie docker start aby wystartować istniejący zakończony kontener i docker attach aby się do niego podłączyć i obserwować standardowe wyjście procesu, który jest uruchomiony.
❯ docker start 4f6d73900753
❯ docker attach 4f6d73900753
Uruchomiony działający w tle kontener możemy również w prosty sposób zrestartować.
❯ docker restart 4f6d73900753
Uruchamianie kontenera w tle
Podając parametr -d możemy uruchomić kontener w tle:
❯ docker run -d ubuntu:latest sh -c "while true; do date; sleep 1; done"
Następnie możemy się do niego podłączyć i obserwować standardowe wyjście:
❯ docker attach 4e8c73d5487a
Tue May 24 11:50:44 UTC 2022
Tue May 24 11:50:45 UTC 2022
Tue May 24 11:50:46 UTC 2022
...
Aby zakończyć sesje z kontenerem możemy uruchomić ctrl + c jednak to zastopuje kontener. Jeżeli chcemy tego uniknąć możemy podłączyć się do kontenera z opcją --sig-proxy=false.
❯ docker attach --sig-proxy=false 4e8c73d5487a
Tue May 24 11:50:44 UTC 2022
Tue May 24 11:50:45 UTC 2022
Tue May 24 11:50:46 UTC 2022
...
Po czym gdy uruchomimy ctrl + c kontener dalej będzie działał w tle. Natomiast w celu samego obserwowania logów lepszym pomysłem będzie komenda docker logs omówiona później.
Przekazanie zmiennych środowiskowych podczas uruchamiania kontenera
Dobrą praktyką jest aby nie przechowywać haseł czy też innych danych wrażliwych w obrazach. Zamiast tego lepiej je wstrzykiwać do kontenera podczas jego uruchamiania w następujący sposób.
❯ docker run -d -e APP_ENV=production -e APP_SECRET=DACFC787 myapp:latest
Usuwanie kontenerów
Domyślnie zakończone kontenery nie są usuwane przez Dockera. Jeżeli chcemy uruchomić w kontenerze tylko jedno polecenie i po jego zakończeniu pozbyć się kontenera bez konieczności usuwania go ręcznie możemy skorzystać z opcji --rm.
❯ docker run --rm ubuntu:latest ls -la
Usunięcie kontenera, który działa w tle wygląda następująco.
❯ docker stop 4e8c73d5487a && docker rm 4e8c73d5487a
Tryb interaktywny
Z poprzednich rozważań dowiedzieliśmy się, że kontener dockera zakończy się jeżeli nie będzie procesu, który będzie go "podtrzymywał". Jeżeli jednak mamy potrzebę podłączyć się do konsoli w celu eksploracji systemu plików (przydaje się podczas debugowania) możemy to osiągnąć uruchamiając kontener w trybie interaktywnym w następujący sposób.
❯ docker run -it ubuntu:latest /bin/bash
lub
❯ docker run -it --entrypoint /bin/bash ubuntu:latest
Jeżeli chcemy podłączyć się do już istniejącego kontenera w sposób interaktywny możemy wykorzystać polecenie docker exec.
❯ docker exec -it 4e8c73d5487a /bin/bash
Tworzenie obrazu na podstawie istniejącego kontenera
W trybie interaktywnym, który był poruszony w poprzedniej sekcji możemy bez problemu dokonać dowolnych zmian np. zmienić konfigurację czy też zainstalować potrzebne nam pakiety i zależności. Mamy możliwość niejako zapisania tych zmian tworząc nowy obraz na podstawie zmian, których dokonaliśmy.
❯ docker commit 4e8c73d5487a testimage:1.0
Jednak lepszym i rekomendowanym sposobem na tworzenie obrazów jest plik Dockerfile omówiony wcześniej.
Wyeksportowanie systemu plików kontenera
Wykorzystując polecenie docker export możemy w prosty sposób "zrzucić" aktualny stan systemu plików kontenera np. w celu jego eksploracji w wygodnym dla nas narzędziu i debugowania.
❯ docker export 4e8c73d5487a -o exported.tar
❯ tar -tvf exported.tar | head
-rwxr-xr-x 0 0 0 0 May 24 13:50 .dockerenv
lrwxrwxrwx 0 0 0 0 Apr 28 13:55 bin -> usr/bin
drwxr-xr-x 0 0 0 0 Apr 18 12:28 boot/
drwxr-xr-x 0 0 0 0 May 24 13:50 dev/
-rwxr-xr-x 0 0 0 0 May 24 13:50 dev/console
drwxr-xr-x 0 0 0 0 May 24 13:50 dev/pts/
drwxr-xr-x 0 0 0 0 May 24 13:50 dev/shm/
drwxr-xr-x 0 0 0 0 May 24 13:50 etc/
-rw------- 0 0 0 0 Apr 28 13:56 etc/.pwd.lock
-rw-r--r-- 0 0 0 3028 Apr 28 13:56 etc/adduser.conf
Tworzenie archiwum tar z obrazem
Możesz spotkać się z sytuacją, że maszyna, na której chcesz uruchomić obraz nie ma dostępu do internetu w związku z tym nie będzie w stanie pobrać tego obrazu z zdalnego repozytorium obrazów. Z pomocą przychodzi polecenie docker save, które wyeksportuje nam obraz do archiwum tar.
❯ docker save -o ubuntu:latest.tar ubuntu:latest
Następnie przenosimy archiwum na drugą maszynę z zainstalowanym dockerem i ładujemy wykorzystując polecenie docker load.
❯ docker load -i ubuntu:latest.tar
CMD vs ENTRYPOINT
W sekcji dot. pliku Dockerfile użyliśmy następującej komendy.
CMD ["java", "Hello"]
Powyższe polecenie jest informacją dla Dockera jaki proces a w zasadzie polecenie chcemy uruchomić wewnątrz kontenera gdy ten startuje. Podczas gdy uruchomiliśmy kontener używając polecenia docker run java-hello Docker uruchomił polecenie wskazane przez nas w CMD tj. java. Możemy również napisać polecenie jakie ma być wykonane gdy startujemy kontener.
❯ docker run java-hello ls -la
Przekazując polecenie podczas uruchamiania kontenera nadpisaliśmy te domyślnie, które zapisaliśmy w pliku Dockerfile na samym końcu. W tym momencie zamiast programu w Java na standardowe wejście zostanie wylistowany bieżący katalog.
Polecenie ENTRYPOINT jest w pewnym sensie podobne do CMD. Domyślnie ENTRYPOINT jest ustawiony na wartość sh -c jednak można zmienić tę wartość. CMD nie ma domyślnej wartości więc trzeba ją wskazać. Podając w CMD wartość ls -la tak naprawdę Docker najpierw patrzy na zmienną ENTRYPOINT i domyślnie uruchamia proces powłoki sh -c a jako parametr podaje polecenie podane w CMD. W efekcie wykonywane jest polecenie sh -c ls -la . Dlatego upraszczając można powiedzieć, że wartości podane w CMD są argumentami dla programu wskazanego w ENTRYPOINT, który zostanie uruchomiony. Warto zmienić domyślną wartość dla ENTRYPOINT na proces aplikacji, który chcemy docelowo uruchomić w kontenerze gdyż uruchamianie dodatkowo powłoki raczej nie ma większego zastosowania chyba, że aplikację startujemy skryptem powłoki.
Przekierowanie standardowych strumieni kontenera
Warto wiedzieć, że Docker mapuje na zewnątrz standardowe strumienie tj. STDOUT i STDERR a także kody wyjściowe procesu uruchomionego w kontenerze.
❯ docker run --rm ubuntu:latest cat /etc/passwd > pass
❯ echo $?
0
Może mieć to szerokie zastosowanie w aplikacjach, które dynamicznie uruchamiają kontenery na żądanie użytkownika i zaczytują rezultat z STDOUT. Uruchamianie poleceń bezpośrednio na serwerze nie byłoby dobrym pomysłem z punktu widzenia bezpieczeństwa natomiast wykonanie tego w kontenerze jest zdecydowanie lepszym rozwiązaniem ponieważ dzięki izolacji polecenie w żaden sposób nie zaszkodzi środowisku wykonawczemu hosta.
Logi
W celu pobrania wszystkich logów z kontenera wykonujemy następującą komendę przekazując w parametrze identyfikator kontenera.
❯ docker logs 4e8c73d5487a
Aby widzieć logi w trybie śledzącym używamy parametru -f
❯ docker logs -f 4e8c73d5487a
Mamy również możliwość filtrowania logów w różny sposób.
❯ docker logs --since=1h 4e8c73d5487a // logi z ostatniej godziny
❯ docker logs --since=3m -f 4e8c73d5487a // logi z ostatnich 3 minut w trybie śledzącym
❯ docker logs --tail=20 -f 4e8c73d5487a // ostatnie 20 linni w trybie śledzącym
Woluminy
Różne aplikacje często zapisują stan do systemu plików. Aby mieć dostęp do danych aplikacji i zachować stan pomiędzy restartowaniem kontenera (np. aktualizacja aplikacji do nowej wersji) możemy użyć woluminów. Dzięki nim mamy możliwość zmapowania katalogu hosta i zamontowania go pod kontener dockera. W celu definicji woluminu dla kontenera możemy użyć parametru -v.
❯ docker run -v $(pwd):/tmp/test --rm ubuntu:latest bash -c "echo 'Hello' > /tmp/test/file.txt"
❯ cat file.txt
Hello
Dlaczego nie możemy zdefiniować tego mapowania w pliku Dockerfile? Ponieważ plik Dockerfile zawiera tylko komendy dot. docelowego obrazu odpowiedzialne za poprawne zbudowanie tego obrazu. Zewnętrzne zasoby, mapowania systemu plików, portów itd. są elementami na styku obrazu i środowiska, na którym ten obraz chcemy wdrożyć i uruchomić w postaci kontenera. Z pewnością nie chcemy aby nasz obraz mocno zależał od tego środowiska.
Podłączanie się do usług hosta wewnątrz kontenera
W przypadku gdy mamy na hoście zainstalowaną jakąś usługę np. mysql połączenie się z nią w środku kontenera używając localhost:3306 nie zadziała. Zamiast tego możemy użyć specjalnej nazwy domenowej host.docker.internal:3306.
.dockerignore
Plik .dockerignore pełni podobną rolę co .gitignore w systemie kontroli wersji. Umieszczamy go obok pliku Dockerfile. Plik ten zawiera zestaw reguł, które informują Dockera, które pliki i katalogi powinien wykluczyć z build kontekstu. Często możemy spotkać się z kopiowaniem do kontenera całego katalogu z kodem aplikacji w następujący sposób.
COPY . /var/www/html
W naszym repozytorium aplikacji może być wiele różnych plików, które niekoniecznie są potrzebne w obrazie wynikowym np. pliki zawierające hasła i inne wrażliwe dane lub pliki tymczasowe. Dzięki .dockerignore możemy je wykluczyć. Dzięki temu nie tylko zmniejszymy rozmiar obrazu ale również przyśpieszymy jego budowanie ze względu na cache invalidation. Każde polecenie COPY czy też ADD tworzy nową warstwę obrazu. Jeżeli pliki, w którego kontekście COPY jest wykonywane uległy modyfikacji co często się zdarza np. pliki z logami, warstwa będzie musiała zostać przebudowana. Wydłuży to proces budowania obrazu dlatego warto wykluczyć tego typu pliki w .dockerignore. Poniżej przykładowy plik .dockerignore.
.git
.cache
*.md
**/*.class
passwords.txt
logs/
Dobre praktyki podczas używania Dockera
Nie używaj tagu latest w środowisku produkcyjnym
Tag latest jest wygodny w użytkowaniu jednak nie sprawdza się w dłuższym horyzoncie czasowym. Gdy korzystasz z tagu latest Twoje wdrożenia nie są powtarzalne ponieważ wersja obrazu jest dynamiczna i może się zmieniać. Może to łatwo doprowadzić do sytuacji gdy nie masz tej samej wersji aplikacji uruchomionej na wszystkich serwerach.
Używaj zmiennych środowiskowych w celu konfiguracji aplikacji
Dzięki umieszczeniu informacji konfiguracyjnych poza repozytorium kodu źródłowego bardzo proste jest uruchamianie dokładnie tego samego kontenera w różnych środowiskach bez wprowadzania zmian w repozytorium a co istotne w repozytorium nie zostają zapisane dane wrażliwe. Co ważniejsze pozwala to na dokładniejsze przetestowanie kontenerów przed wdrożeniem ich na środowisko produkcyjne ponieważ ten sam obraz jest używany we wszystkich środowiskach.
Unikaj przechowywania stanu w kontenerach
Aplikacje zamykane w kontenerach powinny być traktowane jako efemeryczne tzn. mogą łatwo się pojawiać, restartować lub znikać. Jeżeli taki kontener zapisuje stan do swojego systemu plików np. sesję http proces aktualizacji aplikacji do nowej wersji spowoduje usunięcie wszystkich danych z lokalnego stanu aplikacji. Dlatego jeśli to możliwe preferowane jest pisanie aplikacji, które nie muszą przechowywać informacji o stanie dłużej niż przez czas potrzebny na przetworzenie pojedynczego zapytania i udzielenie odpowiedzi. Dzięki temu zatrzymanie któregokolwiek kontenera aplikacji w minimalny sposób wpływa na jego działanie. Gdy trzeba zachować informacje na temat stanu najlepszym podejściem jest użycie zewnętrznego magazynu danych np. Redis, PostgreSQL itp.
Nie używaj użytkownika root
Nie jest dobry pomysłem uruchamianie procesu kontenera z UID=0. W takiej sytuacji każda luka bezpieczeństwa pozwalająca na ominięcie ograniczenia przestrzeni nazw (mechanizm izolacji, który jest wykorzystywany przez dockera) spowoduje, że w systemie będzie działał proces ze wszystkimi uprawnieniami. Aby uruchomić cały kontener z innymi uprawnieniami niż root możesz skorzystać z przełącznika -u np. docker run -d -u 500 my-java-app:1.0.



